Basics
For Stream processing and hence for dagger user must know about some basic concepts and terminologies before using it. Listing some of the important terms and keywords related to dagger/stream processing which will solidify your understanding and help you get started with Dagger.
Terminologies#
Stream Processing#
Stream processing commonly known as Real-Time processing lets users process and query a series of data at the same
time as it is being produced. The source that is producing this data can either be a bounded source such as Parquet Files
or an unbounded source such as Kafka.
Streams#
A Stream defines a logical grouping of a data source and its associated protobuf
schema. All data produced by a source follows the protobuf schema. The source can be an unbounded one such as
KAFKA_SOURCE or KAFKA_CONSUMER in which case, a single stream can consume from one or more topics all sharing the
same schema. Otherwise, the source can be a bounded one such as PARQUET_SOURCE in which case, one or more parquet
files as provided are consumed in a single stream.
Dagger allows creation of multiple streams, each having its own different schema, for use-cases such as SQL joins. However, the SQL queries become more complex as the number of streams increase.
Apache Flink#
Apache Flink is a framework and distributed processing engine for processing over unbounded and bounded data streams. Flink works as the underlying layer of Dagger. Find more information about Flink here.
Time Series Database#
A time-series database (TSDB) is a database optimized for time-stamped or time-series data. Time series data are simply measurements or events that are tracked, monitored, down-sampled, and aggregated over time. Dagger platform used InfluxDB, a Time Series Database as one of its sink for Analytical use cases.
Protobuf#
Protocol buffer or Protobuf is a serialization mechanism for structured data. It’s well optimized to be transferred via the network. Dagger supports processing Data which is in Protobuf format.
Parallelism#
Dagger uses Flink for Distributed Data processing in scale. Slots/Parallelism is the Flink’s unit for Parallel Processing Data which provides an efficient way to horizontally scale up your job.
Dagger Queries#
Dagger supports Streaming SQL support on streams which we call Dagger Queries. These queries are similar to standard ANSI SQL with some more additional syntax.
Function#
Dagger supports some SQL functions out of the box to be used in the queries. Most Apache Calcite supported functions are supported in Dagger with the exceptions of some functions. Flink also supports some generic functions.
User Defined Functions(UDF)#
If Calcite and Flink do not support your desired function, it is pretty easy to expose new custom functions to Dagger which we call User Defined Functions. List of supported UDFs in Dagger.
Windowing#
Time Windows are at the heart of processing infinite streams. As Data being ingested to streams are unbounded and infinite, time windows provide a mechanism to split the stream into “buckets” of finite size, over which we can apply computations.
Dagger provides two different types of windows
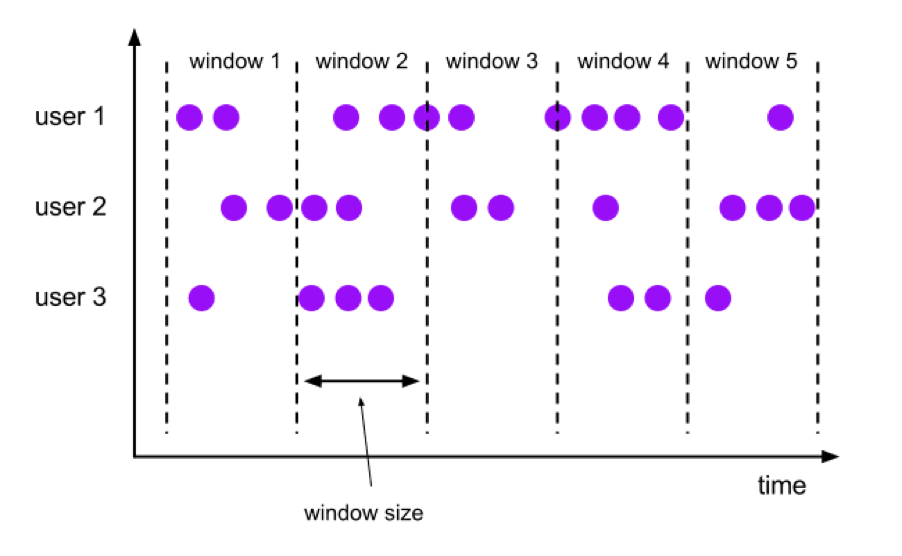
Hop/Tumbling Windows
Each element to a window of specified window size. Tumbling windows have a fixed size and do not overlap. For example, if you specify a tumbling window with a size of 5 minutes, the current window will be evaluated and a new window will be started every five minutes as illustrated by the following figure. (image credit: Flink Operators)
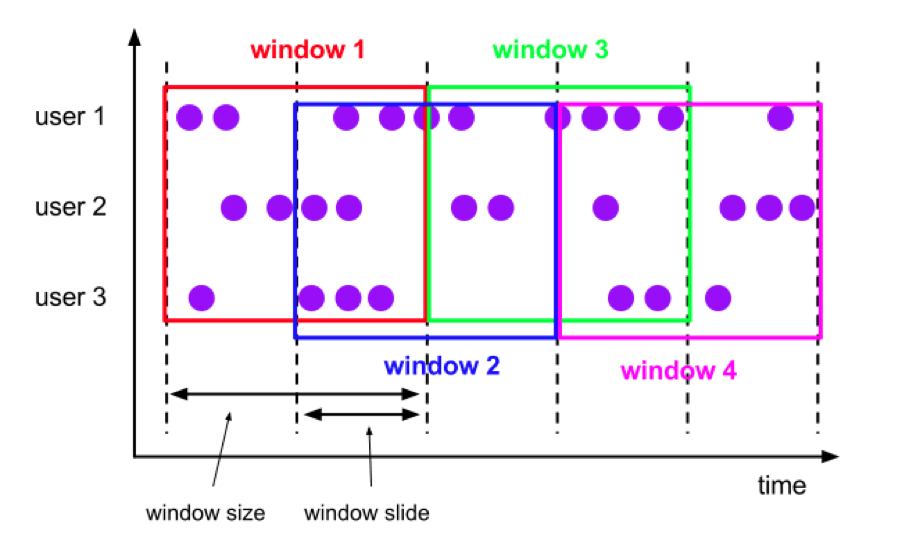
Sliding Windows
Each element gets assigned to windows of fixed length. An additional window slide parameter controls how frequently a sliding window is started. Hence, sliding windows can be overlapping if the slide is smaller than the window size. In this case, elements are assigned to multiple windows. (image credit: Flink Operators)
Rowtime#
Rowtime is the time attribute field in your Data streams on which you can run your time windowed aggregations. You can configure this while creating a Dagger. Rowtime is the one of the time definition fields in input schema on which Dagger does all time it's time-base Operations. Read here on time attributes.