Introduction
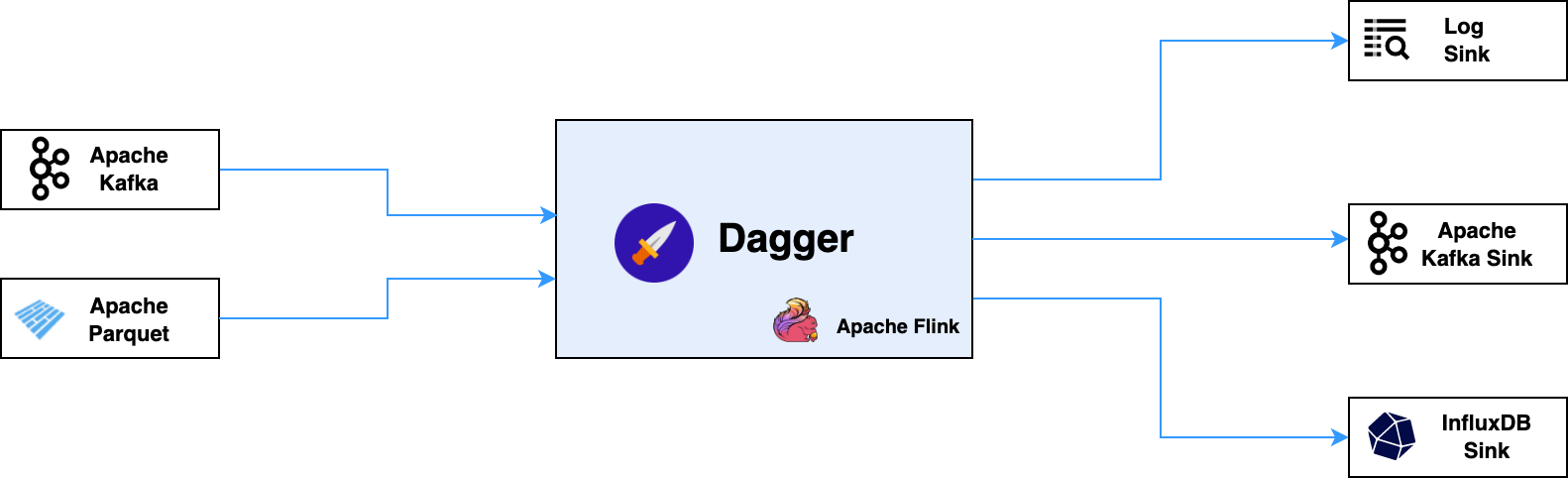
Dagger or Data Aggregator is an easy-to-use, configuration over code, cloud-native framework built on top of Apache Flink for stateful processing of data. With Dagger, you don't need to write custom applications or complicated code to process data as a stream. Instead, you can write SQL queries and UDFs to do the processing and analysis on streaming data.
Key Features#
Discover why to use Dagger
- Processing: Dagger can transform, aggregate, join and enrich streaming data, both real-time and historical.
- Scale: Dagger scales in an instant, both vertically and horizontally for high performance streaming sink and zero data drops.
- Extensibility: Add your own sink to dagger with a clearly defined interface or choose from already provided ones. Use Kafka and/or Parquet Files as stream sources.
- Flexibility: Add custom business logic in form of plugins (UDFs, Transformers, Preprocessors and Post Processors) independent of the core logic.
- Metrics: Always know what’s going on with your deployment with built-in monitoring of throughput, response times, errors and more.
Usecases#
- Map reduce with SQL
- Aggregation with SQL, UDFs
- Enrichment with Post Processors
- Data Masking with Hash Transformer
- Data Deduplication with Transformer
- Realtime long window processing with Longbow
To know more, follow the detailed documentation.
Where to go from here#
Explore the following resources to get started with Dagger:
- Guides provides guidance on creating Dagger with different sinks.
- Concepts describes all important Dagger concepts.
- Advance contains details regarding advance features of Dagger.
- Reference contains details about configurations, metrics and other aspects of Dagger.
- Contribute contains resources for anyone who wants to contribute to Dagger.
- Usecase describes examples use cases which can be solved via Dagger.
- Examples contains tutorials to try out some of Dagger's features with real-world usecases