Post Processors
Post Processors give the capability to do custom stream processing after the SQL processing is performed. Complex transformation, enrichment & aggregation use cases are difficult to execute & maintain using SQL. Post Processors solve this problem through code and/or configuration. This can be used to enrich the stream from external sources (HTTP, ElasticSearch, PostgresDB, GRPC), enhance data points using function or query and transform through user-defined code.
All the post processors mentioned in this doc can be applied in a sequential manner, which enables you to get information from multiple different external data sources and apply as many transformers as required. The output of one processor will be the input for the other and the final result will be pushed to the configured sink.
Flow of Execution
In the flow of Post Processors, all types of processors viz; External Post Processors, Internal Post Processors and Transformers can be applied sequentially via config. The output of one Post Processor will be the input of the next one. The input SQL is executed first before any of the Post Processors and the Post Processors run only on the output of the SQL. Here is an example of a simple use case that can be solved using Post Processor and sample Data flow Diagrams for that.
- Let's assume that you want to find cashback given for a particular order number from an external API endpoint. You can use an HTTP external post-processor for this. Here is a basic Data flow diagram.
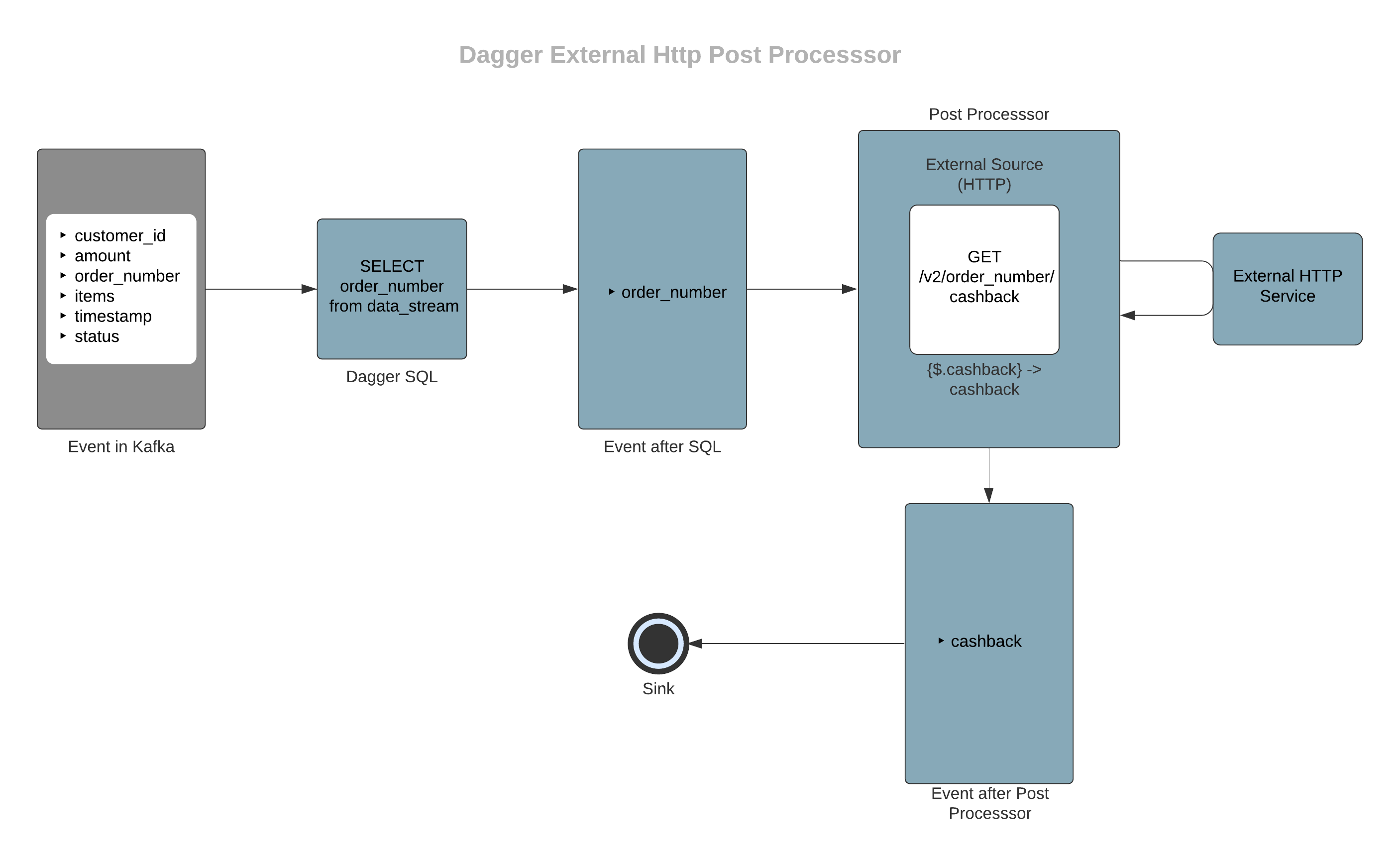
- In the above example, assume you also want to output the information of customer_id and amount which are fields from input proto. Internal Post Processor can be used for selecting these fields from the input stream.
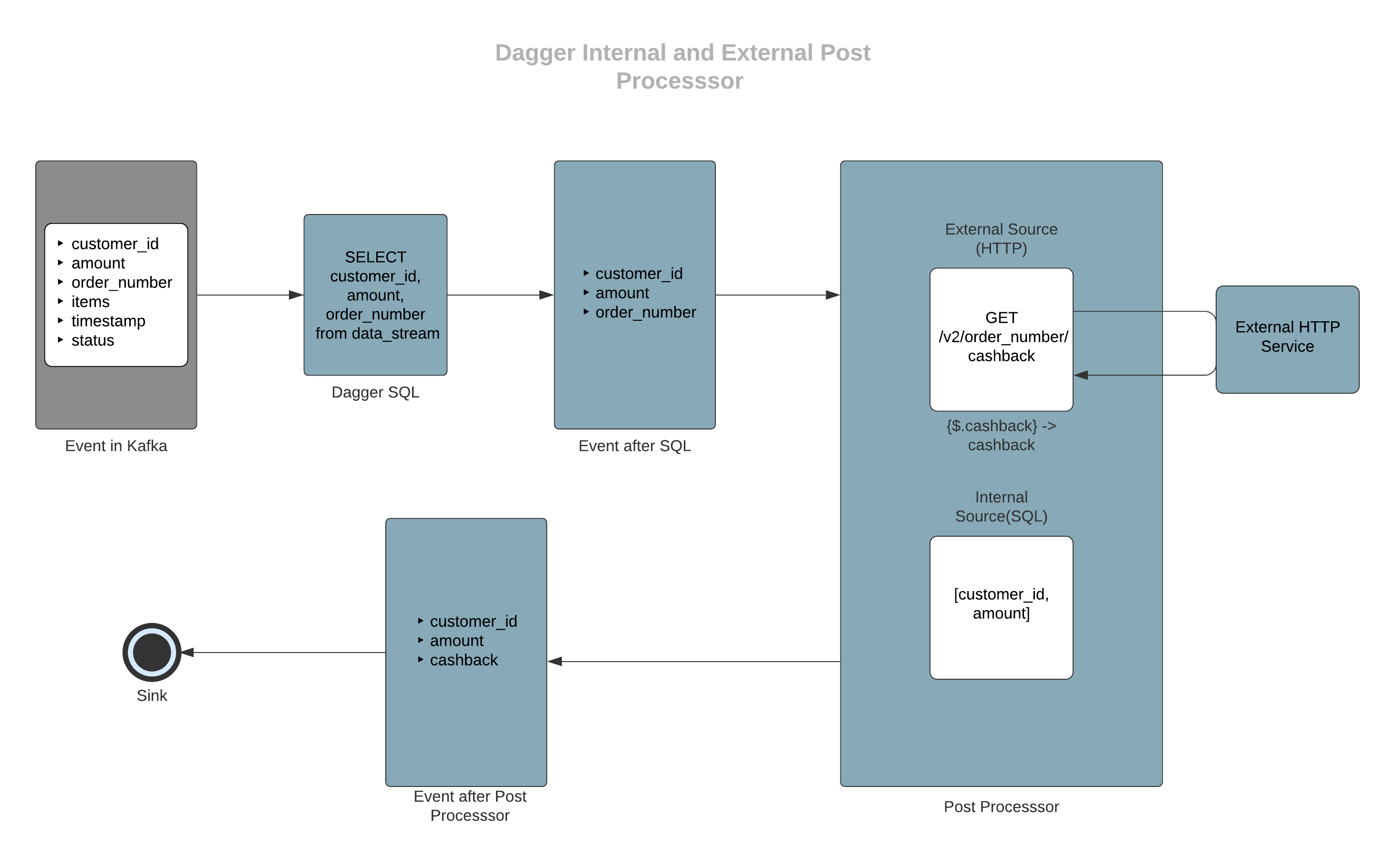
After getting customer_id, amount and cashback amount, you may want to round off the cashback amount. For this, you can write a custom transformer which is a simple Java Flink Map function to calculate the round-off amount.
Note: All the above processors are chained sequentially on the output of the previous processor. The order of execution is determined via the order provided in JSON config.
![]()
Types of Post Processors
There are three types of Post Processors :
Post Processors are entirely configuration driven. All the Post Processor related configs should be configured as part of PROCESSOR_POSTPROCESSOR_CONFIG JSON under Settings in Dagger creation flow. Multiple Post Processors can be combined in the same configuration and applied to a single Dagger.
External Post Processor#
External Post Processor is the one that connects to an external data source to fetch data in an async manner and perform enrichment of the stream message. These kinds of Post Processors use Flink’s API for asynchronous I/O with external data stores. For more details on Flink’s Async I/O find the doc here.
Currently, we are supporting four external sources.
Elasticsearch#
This allows you to enrich your data stream with the data on any remote Elasticsearch. For example, let's say you have payment transaction logs in the input stream but user profile information in Elasticsearch, then you can use this post processor to get the profile information in each record.
Workflow#
On applying only this post processor, dagger will perform the following operations on a single message in happy path
- Consume the message from configured Kafka stream.
- Apply the SQL query configured.
- Generate the endpoint URL using endpoint_pattern and endpoint_variables.
- Make the Elasticsearch call.
- Read the response from Elasticsearch and populate the message according to output_mapping.
- Push the enriched message to configured sink.
Configuration#
Following variables need to be configured as part of PROCESSOR_POSTPROCESSOR_CONFIG JSON
host#
IP(s) of the nodes/haproxy.
- Example value:
localhost - Type:
required
port#
Port exposed for the same.
- Example value:
9200 - Type:
required
user#
Username for Elasticsearch.
- Example value:
testuser - Type:
optional
password#
Password for Elasticsearch.
- Example value:
test - Type:
optional
endpoint_pattern#
String template for the endpoint. This will be appended to the host to create the final URL.
- Example value:
/customers/customer/%s - Type:
required
endpoint_variables#
Comma-separated list of variables used for populating identifiers in endpoint_pattern.
- Example value:
customer_id - Type:
optional
retain_response_type#
If true it will not cast the response from ES to output proto schema. The default behaviour is to cast the response to the output proto schema.
- Example value:
false - Type:
optional - Default value:
false
retry_timeout#
Timeout between request retries in ms.
- Example value:
5000 - Type:
required
socket_timeout#
The time waiting for data after establishing the connection in ms; maximum time of inactivity between two data packets.
- Example value:
6000 - Type:
required
connect_timeout#
The timeout value for ES client in ms.
- Example value:
5000 - Type:
required
capacity#
This parameter(Async I/O capacity) defines how many max asynchronous requests may be in progress at the same time.
- Example value:
30 - Type:
required
output_mapping#
Mapping of fields in output Protos goes here. Based on which part of the response data to use, you can configure the path, and output message fields will be populated accordingly. You can use JsonPath to select fields from json response.
- Example value:
{"customer_profile":{ "path":"$._source"}} - Type:
required
fail_on_errors#
A flag for deciding whether the job should fail on encountering errors or not. If set false the job won’t fail and enrich with empty fields otherwise the job will fail.
- Example value:
false - Type:
optional - Default value:
false
metric_id#
Identifier tag for metrics for every post processor applied. If not given it will use indexes of post processors in the JSON config.
- Example value:
test_id - Type:
optional
Sample Query#
You can select the fields that you want to get from the input stream or you want to use for making the request.
SELECT customer_id from `booking`Sample Configuration#
PROCESSOR_POSTPROCESSOR_ENABLE = truePROCESSOR_POSTPROCESSOR_CONFIG = { "external_source": { "es": [ { "host": "127.0.0.1", "port": "9200", "endpoint_pattern": "/customers/customer/%s", "endpoint_variables": "customer_id", "retry_timeout": "5000", "socket_timeout": "6000", "stream_timeout": "5000", "connect_timeout": "5000", "capacity": "30", "output_mapping": { "customer_profile": { "path": "$._source" } } } ] }}Note: Though it is subjective to a lot of factors like data in ES, throughput in Kafka, size of ES cluster. A good thumb of rule is to make index call rather than queries to ES for fetching the data.
HTTP#
HTTP Post Processor connects to an external API endpoint and does enrichment based on data from the response of the API call. Currently, we support POST, PUT and GET verbs for the API call.
Workflow#
On applying only this post processor, dagger will perform the following operations on a single message in happy path
- Consume the message from configured Kafka stream.
- Apply the SQL query configured.
- Generate the endpoint URL in case of GET call or request body in case of POST/PUT call using request_pattern and request_variables.
- Make the HTTP call.
- Read the response from HTTP API and populate the message according to output_mapping.
- Push the enriched message to configured sink.
Configuration#
Following variables need to be configured as part of PROCESSOR_POSTPROCESSOR_CONFIG JSON
endpoint#
API endpoint. For POST and PUT call, URL will be a combination of endpoint and endpoint_variables. For GET, URL will be a combination of endpoint, endpoint_variables and request pattern.
- Example value:
http://127.0.0.1/api/customerorhttp://127.0.0.1/api/customer/%s - Type:
required
endpoint_variables#
List of comma-separated parameters to be replaced in endpoint, these variables must be present in the input proto and selected via the SQL query. Endpoint should also contains %s.
- Example value:
customer_id - Type:
optional
verb#
HTTP verb (currently support POST, PUT and GET).
- Example value:
GET - Type:
required
request_pattern#
Template for the body in case of POST/PUT and endpoint path in case of GET.
- Example value:
/customers/customer/%s - Type:
required
request_variables#
List of comma-separated parameters to be replaced in request_pattern, these variables must be present in the input proto and selected via the SQL query.
- Example value:
customer_id - Type:
optional
header_pattern#
Template for the dynamic headers.
- Example value:
{"key": "%s"} - Type:
optional
header_variables#
List of comma-separated parameters to be replaced in header_pattern, these variables must be present in the input proto and selected via the SQL query.
- Example value:
customer_id - Type:
optional
stream_timeout#
The timeout value for the stream in ms.
- Example value:
5000 - Type:
required
connect_timeout#
The timeout value for HTTP client in ms.
- Example value:
5000 - Type:
required
fail_on_errors#
A flag for deciding whether the job should fail on encountering errors(timeout and status codes apart from 2XX) or not. If set false the job won’t fail and enrich with empty fields otherwise the job will fail.
- Example value:
false - Type:
optional - Default value:
false
exclude_fail_on_errors_code_range#
Defines the exclusion range of HTTP status codes for which job should not fail if fail_on_errors is true.
- Example value:
400,404-499 - Type:
optional
capacity#
This parameter(Async I/O capacity) defines how many max asynchronous requests may be in progress at the same time.
- Example value:
30 - Type:
required
headers#
Key-value pairs for adding headers to the request.
- Example value:
{"content-type": "application/json"} - Type:
optional
retain_response_type#
If true it will not cast the response from HTTP to output proto schema. The default behaviour is to cast the response to the output proto schema.
- Example value:
false - Type:
optional - Default value:
false
output_mapping#
Mapping for all the fields we need to populate from the API response providing a path to fetch the required field from the response body. You can use JsonPath to select fields from json response.
- Example value:
{"customer_profile":{ "path":"$._source"}} - Type:
required
metric_id#
Identifier tag for metrics for every post processor applied. If not given it will use indexes of post processors in the JSON config.
- Example value:
test_id - Type:
optional
Sample Query#
You can select the fields that you want to get from the input stream or you want to use for making the request.
SELECT customer_id from `booking`Sample Configuration for GET#
PROCESSOR_POSTPROCESSOR_ENABLE = truePROCESSOR_POSTPROCESSOR_CONFIG = { "external_source": { "http": [ { "endpoint": "http://127.0.0.1", "verb": "get", "request_pattern": "/customers/customer/%s", "request_variables": "customer_id", "header_pattern": "{\"Header_Key\": \"%s\"}", "header_variables": "wallet_id", "stream_timeout": "5000", "connect_timeout": "5000", "fail_on_errors": "false", "capacity": "30", "headers": { "content-type": "application/json" }, "output_mapping": { "customer_profile": { "path": "$._source" } } } ] }}Note: In case you want to use all the fields along with a modified/nested field you can use “select *, modified_field as custom_column_name from data_stream”.
Sample Configuration for POST#
PROCESSOR_POSTPROCESSOR_ENABLE = truePROCESSOR_POSTPROCESSOR_CONFIG = { "external_source": { "http": [ { "endpoint": "http://127.0.0.1/customer", "verb": "post", "request_pattern": "{'key': \"%s\"}", "request_variables": "customer_id", "stream_timeout": "5000", "connect_timeout": "5000", "fail_on_errors": "false", "capacity": "30", "headers": { "content-type": "application/json" }, "output_mapping": { "test_field": { "path": "$._source" } } } ] }}Note: Post request patterns support both primitive and complex data types. But for complex objects, you need to remove the quotes from the selector ( %s). So in the case of a primitive datapoint of string the selector will be (”%s”) whereas for complex fields it will be (%s).
Postgres#
This allows you to enrich your data stream with the data on any remote Postgres. For example, let's say you have payment transaction logs in the input stream but user profile information in Postgres, then you can use this post processor to get the profile information in each record. Currently, we support enrichment from PostgresDB queries that result in a single row from DB.
Workflow#
On applying only this post processor, dagger will perform the following operations on a single message in happy path
- Consume the message from configured Kafka stream.
- Apply the SQL query configured.
- Generate the Postgres query using query_pattern and query_variables.
- Make the Postgres call.
- Read the response from Postgres and populate the message according to output_mapping.
- Push the enriched message to configured sink.
Configuration#
Following variables need to be configured as part of PROCESSOR_POSTPROCESSOR_CONFIG JSON
host#
IP(s) of the nodes/haproxy.
- Example value:
http://127.0.0.1 - Type:
required
port#
Port exposed for the same.
- Example value:
5432 - Type:
required
user#
Username for Postgres.
- Example value:
testuser - Type:
required
password#
Password for the particular user.
- Example value:
test - Type:
required
database#
Postgres database name.
- Example value:
testdb - Type:
required
query_pattern#
SQL query pattern to populate the data from PostgresDB.
- Example value:
select email, phone from public.customers where customer_id = '%s' - Type:
required
query_variables#
This is a comma-separated list (without any whitespaces in between) of parameters to be replaced in the query_pattern, and these variables must be present in the input proto.
- Example value:
customer_id - Type:
optional
stream_timeout#
The timeout value for the stream in ms.
- Example value:
25000 - Type:
required
idle_timeout#
The timeout value for Postgres connection in ms.
- Example value:
25000 - Type:
required
connect_timeout#
The timeout value for client in ms.
- Example value:
25000 - Type:
required
fail_on_errors#
A flag for deciding whether the job should fail on encountering errors or not. If set false the job won’t fail and enrich with empty fields otherwise the job will fail.
- Example value:
false - Type:
optional - Default value:
false
capacity#
This parameter(Async I/O capacity) defines how many max asynchronous requests may be in progress at the same time.
- Example value:
30 - Type:
required
retain_response_type#
If true it will not cast the response from Postgres Query to output proto schema. The default behaviour is to cast the response to the output proto schema.
- Example value:
false - Type:
optional - Default value:
false
output_mapping#
Mapping of fields in output proto goes here. Based on which part of the response data to use, you can configure the path, and output message fields will be populated accordingly.
- Example value:
{"customer_email": "email","customer_phone": "phone”} - Type:
required
metric_id#
Identifier tag for metrics for every post processor applied. If not given it will use indexes of post processors in the JSON config.
- Example value:
test_id - Type:
optional
Sample Query#
You can select the fields that you want to get from the input stream or you want to use for making the request.
SELECT customer_id from `booking`Sample Configuration#
PROCESSOR_POSTPROCESSOR_ENABLE = truePROCESSOR_POSTPROCESSOR_CONFIG = { "external_source": { "pg": [ { "host": "http://127.0.0.1", "port": "5432", "user": "test", "password": "test", "database": "my_db", "capacity": "30", "stream_timeout": "25000", "connect_timeout": "25000", "idle_timeout": "25000", "query_pattern": "select email, phone from public.customers where customer_id = '%s'", "query_variables": "customer_id", "output_mapping": { "customer_email": "email", "customer_phone": "phone” }, "fail_on_errors": "true" } ] }}Note: If you want to use % as a special character in your Postgres query, you’ll need to provide an additional % with it as an escape character so that Java doesn’t take it as a string formatter and try to format it, which in turn might end up in invalid format exception. E.g. "select email, phone from public.customers where name like '%%smith'"
Note: Please add relevant indexing in the database to ensure adequate performance.
GRPC#
This enables you to enrich the input streams with any information available via remote gRPC server. For example let's say you have payment transaction logs in the input stream but user profile information available via a gRPC service, then you can use this post processor to get the profile information in each record. Currently, we support only Unary calls.
Workflow#
On applying only this post processor, dagger will perform the following operations on a single message in happy path
- Consume the message from configured Kafka stream.
- Apply the SQL query configured.
- Generate the gRPC request using request_pattern and request_variables.
- Make the gRPC call.
- Read the response from gRPC API and populate the message according to output_mapping.
- Push the enriched message to configured sink.
Configuration#
Following variables need to be configured as part of PROCESSOR_POSTPROCESSOR_CONFIG JSON
endpoint#
Hostname of the gRPC endpoint.
- Example value:
localhost - Type:
required
service_port#
Port exposed for the service.
- Example value:
5000 - Type:
required
grpc_stencil_url#
Endpoint where request and response proto descriptors are present. If not there, it will try to find from the given stencil_url of the input and output proto of Dagger.
- Example value:
http://localhost:9000/proto-descriptors/latest - Type:
optional
grpc_request_proto_schema#
Proto schema for the request for the gRPC endpoint.
- Example value:
io.grpc.test.Request - Type:
required
grpc_response_proto_schema#
Proto schema for the response from the gRPC endpoint.
- Example value:
io.grpc.test.Response - Type:
required
grpc_method_url#
Url of the gRPC method exposed.
- Example value:
testserver.test/ReturnResponse - Type:
required
request_pattern#
JSON Pattern for the request.
- Example value:
{'key': %s} - Type:
required
request_variables#
This is a comma-separated list of parameters to be replaced in the request_pattern, and these variables must be present in the input proto.
- Example value:
customer_id - Type:
optional
stream_timeout#
The timeout value for the stream in ms.
- Example value:
5000 - Type:
required
connect_timeout#
The timeout value for gRPC client in ms.
- Example value:
5000 - Type:
required
grpc_arg_keepalive_time_ms#
The keepalive ping is a way to check if a channel is currently working by sending HTTP2 pings over the transport. It is sent periodically, and if the ping is not acknowledged by the peer within a certain timeout period, the transport is disconnected. Other keepalive configurations are described here.
This channel argument controls the period (in milliseconds) after which a keepalive ping is sent on the transport. If smaller than 10000, 10000 will be used instead.
- Example value:
60000 - Type:
optional - Default value:
infinite
grpc_arg_keepalive_timeout_ms#
This channel argument controls the amount of time (in milliseconds) the sender of the keepalive ping waits for an acknowledgement. If it does not receive an acknowledgment within this time, it will close the connection.
- Example value:
5000 - Type:
optional - Default value:
20000
fail_on_errors#
A flag for deciding whether the job should fail on encountering errors or not. If set false the job won’t fail and enrich with empty fields otherwise the job will fail.
- Example value:
false - Type:
optional - Default value:
false
capacity#
This parameter(Async I/O capacity) defines how many asynchronous requests may be in progress at the same time.
- Example value:
30 - Type:
required
headers#
Key-value pairs for adding headers to the request.
- Example value:
{'key': 'value'} - Type:
optional
retain_response_type#
If true it will not cast the response from gRPC endpoint to output proto schema. The default behaviour is to cast the response to the output proto schema.
- Example value:
false - Type:
optional - Default value:
false
output_mapping#
Mapping of fields in output proto goes here. Based on which part of the response data to use, you can configure the path, and output message fields will be populated accordingly. You can use JsonPath to select fields from json response.
- Example value:
{"customer_profile":{ "path":"$._source"}} - Type:
required
metric_id#
Identifier tag for metrics for every post processor applied. If not given it will use indexes of post processors in the JSON config.
- Example value:
test_id - Type:
optional
Sample Query#
You can select the fields that you want to get from the input stream or you want to use for making the request.
SELECT customer_id from `booking`Sample Configuration#
PROCESSOR_POSTPROCESSOR_ENABLE = truePROCESSOR_POSTPROCESSOR_CONFIG = { "external_source": { "grpc": [ { "endpoint": "localhost", "service_port": "5000", "request_pattern": "{'key': %s}", "request_variables": "customer_id", "grpc_stencil_url": "http://localhost:9000/proto-descriptors/latest", "grpc_request_proto_schema": "io.grpc.test.Request", "grpc_response_proto_schema": "io.grpc.test.Response", "grpc_method_url": "testserver.test/ReturnResponse", "stream_timeout": "5000", "connect_timeout": "5000", "fail_on_errors": "false", "capacity": "30", "headers": { "key": "value" }, "output_mapping": { "customer_profile": { "path": "$._source" } } } ] }}Internal Post Processor#
In order to enhance output with data that doesn’t need an external data store, you can use this configuration. At present, we support 3 types.
- SQL: Data fields from the SQL query output. You could either use a specific field or
*for all the fields. In case of selecting*you have the option to either map all fields to single output field or multiple output fields with the same name. Check the example in sample configuration. - Constant: Constant value without any transformation.
- Function: Predefined functions (in Dagger) which will be evaluated at the time of event processing. At present, we support only the following 2 functions:
CURRENT_TIMESTAMP, which can be used to populate the latest timestamp.JSON_PAYLOAD, which can be used to get the entire incoming proto message as a JSON string. For this function to work correctly, ensure that the Dagger SQL outputs rows in the same format as the proto class specified ininternal_processor_configfield (check the function example in sample configuration).
Workflow#
On applying only this post processor, dagger will perform the following operations on a single message in happy path
- Consume the message from configured Kafka stream.
- Apply the SQL query configured.
- Populate the provided output_field with the value depending upon the type.
- Push the populated message to configured sink.
Configuration#
Following variables need to be configured as part of PROCESSOR_POSTPROCESSOR_CONFIG JSON
output_field#
The field in output proto where this field should be populated.
- Example value:
event_timestamp - Type:
required
value#
The input data.
- Example value:
CURRENT_TIMESTAMP - Type:
required
type#
The type of internal post processor. This could be ‘SQL’, ‘constant’ or ‘function’ as explained above.
- Example value:
function - Type:
required
internal_processor_config#
The configuration argument needed to specify inputs for certain function type internal post processors. As of now, this is only required for JSON_PAYLOAD internal post processor.
- Example value:
{"schema_proto_class": "com.gotocompany.dagger.consumer.TestBookingLogMessage"} - Type:
optional
Sample Query#
You can select the fields that you want to get from the input stream or you want to use for making the request.
SELECT * from `booking`Sample Configurations#
SQL
This configuration will populate field booking_log with all the input fields selected in the SQL
PROCESSOR_POSTPROCESSOR_ENABLE = truePROCESSOR_POSTPROCESSOR_CONFIG = { "internal_source": [ { "output_field": "booking_log", "type": "sql", "value": "*" } ]}In order to select all fields and map them to multiple fields with same name in the output proto
PROCESSOR_POSTPROCESSOR_ENABLE = truePROCESSOR_POSTPROCESSOR_CONFIG = { "internal_source": [ { "output_field": "*", "type": "sql", "value": "*" } ]}Constant
This configuration will populate field s2id_level with value 13 for all the events
PROCESSOR_POSTPROCESSOR_ENABLE = truePROCESSOR_POSTPROCESSOR_CONFIG = { "internal_source": [ { "output_field": "s2id_level", "type": "constant", "value": "13" } ]}Function
This configuration will populate field event_timestamp with a timestamp of when the event is processed.
FLINK_SQL_QUERY=SELECT * from data_streamPROCESSOR_POSTPROCESSOR_ENABLE = truePROCESSOR_POSTPROCESSOR_CONFIG = { "internal_source": [ { "output_field": "event_timestamp", "type": "function", "value": "CURRENT_TIMESTAMP" } ]}Similarly, the following configuration will fill the json_payload field with the complete output of SQL query, in JSON format.
FLINK_SQL_QUERY=SELECT * from data_streamPROCESSOR_POSTPROCESSOR_ENABLE = truePROCESSOR_POSTPROCESSOR_CONFIG = { "internal_source": [ { "output_field": "json_payload", "type": "function", "value": "JSON_PAYLOAD", "internal_processor_config": { "schema_proto_class": "com.gotocompany.dagger.consumer.TestBookingLogMessage" } } ]}Transformers#
Transformers are the type of processors that let users define more complex processing capabilities by writing custom Java code. As this is a vast topic, we have covered it in detail here.
Post Processor requirements
Some basic information you need to know before the creation of a Post Processor Dagger is as follow
Number of Post Processors#
Any number of post processors can be chained in a single dagger for a given use-case. The post-processors could be of the same or different type. The initial SQL do not depend on the number of Post Processors and you can simply start with selecting as many fields that are required for the final result as well as the Post Processors in the SQL.
Throughput#
The throughput depends on the input topic of Dagger and after SQL filtering, the enrichment store should be able to handle that load.
Output Proto#
The output proto should have all the fields that you want to output from the input stream as well as fields getting enriched from the Post Processor with the correct data type.
Connectivity#
The enrichment store should have connectivity to the Dagger deployment.