Architecture
Raccoon written in GO is a high throughput, low-latency service that provides an API to ingest streaming data from mobile apps, sites and publish it to Kafka. Raccoon supports websockets, REST and gRPC protocols for clients to send events. With wesockets it provides long persistent connections, with no overhead of additional headers sizes as in http protocol. Racoon supports protocol buffers and JSON as serialization formats. Websockets and REST API support both whereas with gRPC only protocol buffers are supported. It provides an event type agnostic API that accepts a batch (array) of events in protobuf format. Refer here for data definitions format that Raccoon accepts.
Raccoon was built with a primary purpose to source or collect user behaviour data in near-real time. User behaviour data is a stream of events that occur when users traverse through a mobile app or website. Raccoon powers analytics systems, big data pipelines and other disparate consumers by providing high volume, high throughput ingestion APIs consuming real time data. Raccoon’s key architecture principle is a realization of an event agnostic backend (accepts events of any type without the type awareness). It is this capability that enables Raccoon to evolve into a strong player in the ingestion/collector ecosystem that has real time streaming/analytical needs.
System Design
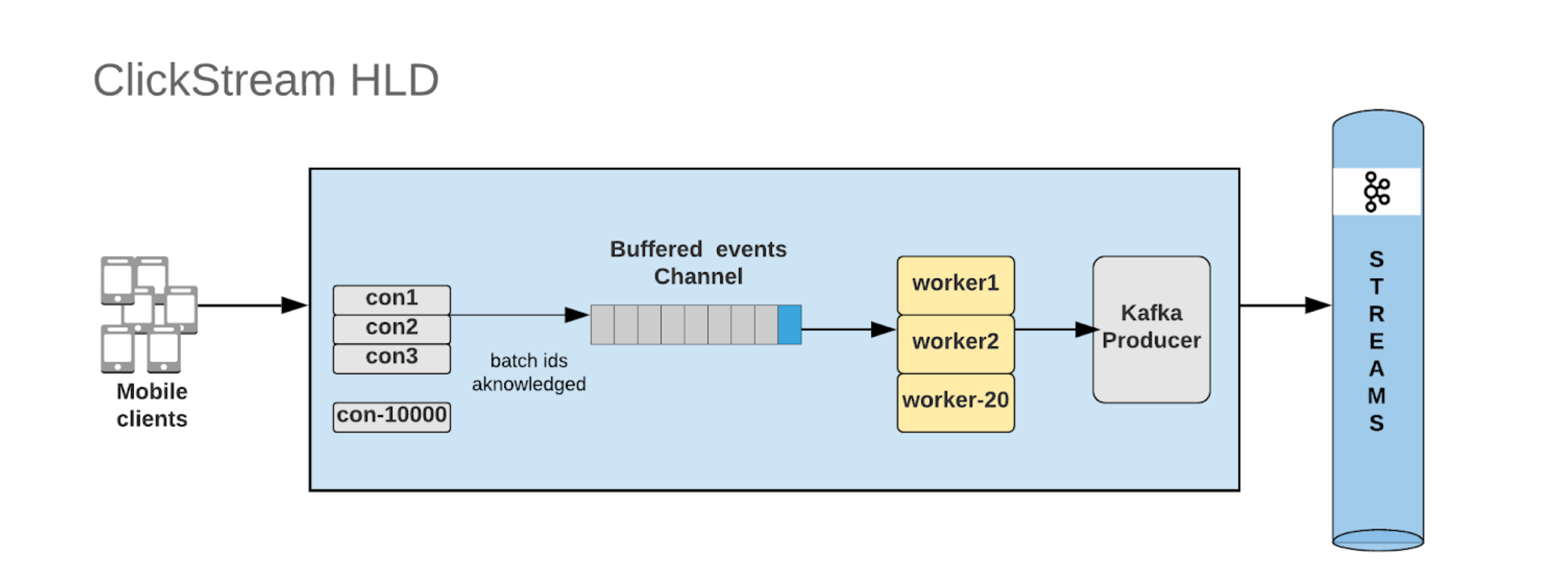
At a high level, the following sequence details the architecture.
- Raccoon accepts events through one of the supported protocols.
- The events are deserialized using the correct deserializer and then forwarded to the buffered channel.
- A pool of worker go routines works off the buffered channel
- Each worker iterates over the events' batch, determines the topic based on the type and serializes the bytes to the Kafka producer synchronously.
Note: The internals of each of the components like channel size, buffer sizes, publisher properties etc., are configurable enabling Raccoon to be provisioned according to the system/event characteristics and load.
Connections
Websockets
Raccoon supports long-running persistent WebSocket connections with the client. Once a client makes an HTTP request with a WebSocket upgrade header, raccoon upgrades the HTTP request to a WebSocket connection end of which a persistent connection is established with the client.
The following sequence outlines the connection handling by Raccoon:
- Clients make websocket connections to Raccoon by performing a http GET API call, with headers to upgrade to websocket.
- Raccoon uses gorilla websocket handlers and for each websocket connection the handlers spawn a goroutine to handle incoming requests.
- After the websocket connection has been established, clients can send the events.
- Construct connection identifier from the request header. The identifier is constructed from the value of
SERVER_WEBSOCKET_CONN_ID_HEADERheader. For example, Raccoon is configured withSERVER_WEBSOCKET_CONN_ID_HEADER=X-User-ID. Raccoon will check the value of X-User-ID header and make it an identifier. Raccoon then uses this identifier to check if there is already an existing connection with the same identifier. If the same connection already exists, Raccoon will disconnect the connection with an appropriate error message as a response proto.- Optionally, you can also configure
SERVER_WEBSOCKET_CONN_GROUP_HEADERto support multi-tenancy. For example, you want to use an instance of Raccoon with multiple mobile clients. You can configure raccoon withSERVER_WEBSOCKET_CONN_GROUP_HEADER=X-Mobile-Client. Then, Raccoon will use the value of X-Mobile-Client along with X-User-ID as identifier. The uniqueness becomes the combination of X-User-ID value with X-Mobile-Client value. This way, Raccoon can maintain the same X-User-ID within different X-Mobile-Client.
- Optionally, you can also configure
- Verify if the total connections have reached the configured limit based on
SERVER_WEBSOCKET_MAX_CONNconfiguration. On reaching the max connections, Raccoon disconnects the connection with an appropriate error message as a response proto. - Upgrade the connection and persist the identifier.
- Add ping/pong handlers on this connection, read timeout deadline. More about these handlers in the following sections
- At this point, the connection is completely upgraded and Raccoon is ready to accept SendEventRequest. The handler handles each SendEventRequest by sending it to the events-channel. The events can be published by the publisher either synchronously or asynchronous based on the configuration.
- When the connection is closed. Raccoon clean up the connection along with the identifier. The same identifier then can be reused on the upcoming connection.
REST
Client connects to the server with the same endpoint but with POST HTTP method. As it is a rest endpoint each request is uniquely handled.
- Connection identifier is constructed from the values of
SERVER_WEBSOCKET_CONN_ID_HEADERandSERVER_WEBSOCKET_CONN_GROUP_HEADERheader here too.
gRPC
It is recommended to generate the gRPC client for Raccoon's EventService and use that client to do gRPC request. Currently only unary requests are supported.
- Client's
SendEventmethod is called to send the event. - Connection identifier is constructed from the values of
SERVER_WEBSOCKET_CONN_ID_HEADERandSERVER_WEBSOCKET_CONN_GROUP_HEADERin gRPC metadata.
Clients can send the request anytime as long as the websocket connection is alive whereas with REST and gRPC requests can be sent only once.
Event Delivery Gurantee (at-least-once for most time)
The server for the most times provide at-least-once event delivery gurantee.
Event data loss happens in the following scenarios:
When the server shutsdown, events in-flight in the kafka buffer or those stored in the internal channels are potentially lost. The server performs, on a best-effort basis, sending all the events to kafka within a configured shutdown time
WORKER_BUFFER_FLUSH_TIMEOUT_MS. The default time is set to 5000 ms within which it is expected that all the events are sent by then.When the upstream kafka cluster is facing a downtime
Every event sent from the client is stored in-memory in the buffered channels (explained in the
Acknowledging eventssection). The workers pull the events from this channel and publishes to kafka. The server does not maintain any event peristence. This is a conscious decision to enable a simpler, performant ingestion design for the server. The buffer/retries of failed events is relied upon Kafka's internal buffer/retries respectively. In future: Server can be augmented for zero-data loss or at-least-once guarantees through intermediate event persitence.
Acknowledging events
Event acknowledgements was designed to signify if the events batch is received and sent to Kafka successfully. This will enable the clients to retry on failed event delivery. Raccoon chooses when to send event acknowledgement based on the configuration parameter EVENT_ACK.
EVENT_ACK = 0
Raccoon sends the acknowledgments as soon as it receives and deserializes the events successfully using the proto SendEventRequest. This configuration is recommended when low latency takes precedence over end to end acknowledgement. The acks are sent even before it is produced to Kafka. The following picture depicts the sequence of the event ack.

Pros:
- Performant as it does not wait for kafka/network round trip for each batch of events.
Cons:
- Potential data-loss and the clients do not get a chance to retry/resend the events. The possiblity of data-loss occurs when the kafka borker cluster is facing a downtime.
EVENT_ACK = 1
Raccoon sends the acknowledgments after the events are acknowledged successfully from the Kafka brokers. This configuration is recommended when reliable end-to-end acknowledgements are required. Here the underlying publisher acknowledgement is leveraged.

Pros:
- Minimal data loss, clients can retry/resend events in case of downtime/broker failures.
Cons:
- Increased end to end latency as clients need to wait for the event to be published.
Considering that kafka is set up in a clustered, cross-region, cross-zone environment, the chances of it going down are mostly unlikely. In case if it does, the amount of events lost is negligible considering it is a streaming system and is expected to forward millions of events/sec.
When an SendEventRequest is sent to Raccoon over any connection be it Websocket/HTTP/gRPC a corresponding response is sent by the server inidcating whether the event was consumed successfully or not.
Supported Protocols and Data formats
| Protocol | Data Format | Version |
|---|---|---|
| WebSocket | Protobufs | v0.1.0 |
| WebSocket | JSON | v0.1.2 |
| REST API | JSON | v0.1.2 |
| REST API | Protobufs | v0.1.2 |
| gRPC | Protobufs | v0.1.2 |
Request and Response Models
Protobufs
When an SendEventRequest proto below containing events are sent over the wire
message SendEventRequest {
//unique guid generated by the client for this request
string req_guid = 1;
// time probably when the client sent it
google.protobuf.Timestamp sent_time = 2;
// actual events
repeated Event events = 3;
}
a corresponding SendEventResponse is sent by the server.
message SendEventResponse {
Status status = 1;
Code code = 2;
/* time when the response is generated */
int64 sent_time = 3;
/* failure reasons if any */
string reason = 4;
/* Usually detailing the success/failures */
map<string, string> data = 5;
}
JSON
When a JSON event like the one metoined below is sent a corresponding JSON response is sent by the server.
Request
{
"req_guid": "1234abcd",
"sent_time": {
"seconds": 1638154927,
"nanos": 376499000
},
"events": [
{
"eventBytes": "Cg4KCHNlcnZpY2UxEgJBMRACIAEyiQEKJDczZTU3ZDlhLTAzMjQtNDI3Yy1hYTc5LWE4MzJjMWZkY2U5ZiISCcix9QzhsChAEekGEi1cMlNAKgwKAmlkEgJpZBjazUsyFwoDaU9zEgQxMi4zGgVBcHBsZSIDaTEwOiYKJDczZTU3ZDlhLTAzMjQtNDI3Yy1hYTc5LWE4MzJjMWZkY2U5Zg==",
"type": "booking"
}
]
}
Response
{
"status": 1,
"code": 1,
"sent_time": 1638155915,
"data": {
"req_guid": "1234abcd"
}
}
Event Distribution
Event distribution works by finding the type for each event in the batch and sending them to appropriate kafka topic. The topic name is determined by the following code
topic := fmt.Sprintf(pr.topicFormat, event.Type)
where topicformat - is the configured pattern EVENT_DISTRIBUTION_PUBLISHER_PATTERN type - is the type set by the client when the event proto is generated
For eg. setting the
EVENT_DISTRIBUTION_PUBLISHER_PATTERN=topic-%s-log
and a type such as type=viewed in the event format
and a type such as type=viewed in the event format
message Event {
/*
`eventBytes` is where you put bytes serialized event.
*/
bytes eventBytes = 1;
/*
`type` denotes an event type that the producer of this proto message may set.
It is currently used by raccoon to distribute events to respective Kafka topics. However the
users of this proto can use this type to set strings which can be processed in their
ingestion systems to distribute or perform other functions.
*/
string type = 2;
}
will have the event sent to a topic like
topic-viewed-log
The event distribution does not depend on any partition logic. So events can be randomnly distrbuted to any kafka partition.
Event Deserialization
The top level wrapper SendEventRequest is deserialized which provides a list of events of type Event proto. This event wrapper composes of serialized bytes, which is the actual event, set in the field bytes inside the Event proto. Raccoon does not open this underlying bytes. The deserialization is used to unwrap the event type and determine the topic that the eventBytes (an event) need to be sent to.
Channels
Buffered Channels are used to store the incoming events' batch. The channel sizes can be configured based on the load & capacity.
Keeping connections alive
The server ensures that the connections are recyclable. It adopts mechanisms to check connection time idleness. The handlers ping clients very 30 seconds (configurable). If the client does not respond within a stipulated time the connection is marked as corrupt. Every subsequent read/write message there after on this connection fails. Raccoon removes the connections post this. Clients can also ping the server while the server responds with pongs to these pings. Clients can programmtically reconnect on failed or corrupt server connections.
Components
Kafka producer
Raccoon uses confluent go kafka as the producer client to publish events. Publishing events are light weight and relies on kafka producer's retries. Confluent internally uses librdkafka which produces events asynchronously. Application writes messages using a functional based producer API
Produce(message, deliveryChannel) -- deliveryChannel is where the delivery reports or acknowledgements are received.
Raccoon internally checks for these delivery reports before pulling the next batch of events. On failed deliveries the appropriate metrics are updated. This mechanism makes the events delivery synchronous and a reliable events delivery.
Observability Stack
Raccoon internally uses statsd go module client to export metrics in StatsD line protocol format. A recommended choice for observability stack would be to host telegraf as the receiver of these measurements and expoert it to influx, influx to store the metrics, grafana to build dashboards using Influx as the source.